Kubernetes应用部署基本原则
在本文中,我将介绍如何设计云原生应用程序并将其部署在 Kubernetes 上的 8 条原则。
原则1:pod多副本
Kubernetes 的自我修复特性,使Kubernetes 可以重启失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。当我们使用deployment或StatefulSet部署工作负载的时候,确保spec.replicas的副本集数量不低于1,dev或uat环境除外。
通过service的负载均衡,运行多个容器实例保障应用的连续性,即使部分容器异常重启也能保障应用的正常访问。
原则2:Secret和ConfigMap灵活使用
配置、密钥等文件可以通过构建到镜像或设置到环境变量中引用,当文件有更新,则需要重新构建镜像发布后生效,无法做到热更新。我们可以通过Kubernetes的volumes挂载方式引用自己创建的secret(密文)或configmap(明文),挂载到容器中指定的目录下做到热更新
原则3:Horizontal Pod Autoscaler (HPA)使用
从来没有人愿意他们的服务在生产环境中耗尽容量。同样,没有人希望因为 Pod 的容量不足影响用户体验。根据可扩展性设计原则,我们应该从一开始就为单pod做好全链路压测,有针对性的设置pod的最小副本数,并为工作负载应对突发流量最好预估,通过cpu内存等百分比设置pod的最大副本数。这对于应用可用性和可扩展性至关重要。(StatefulSet有状态应用也可以使用HPA自动伸缩,不过建议手动触发,例如扩展数据库可能会导致大量数据复制和额外的事务管理发生,如果数据库已经处于高负载状态,这会产生不可控制的问题。此外如果有状态组件需要以某种方式与其他实例同步,请考虑禁用自动缩减。)
原则4:生命周期管理
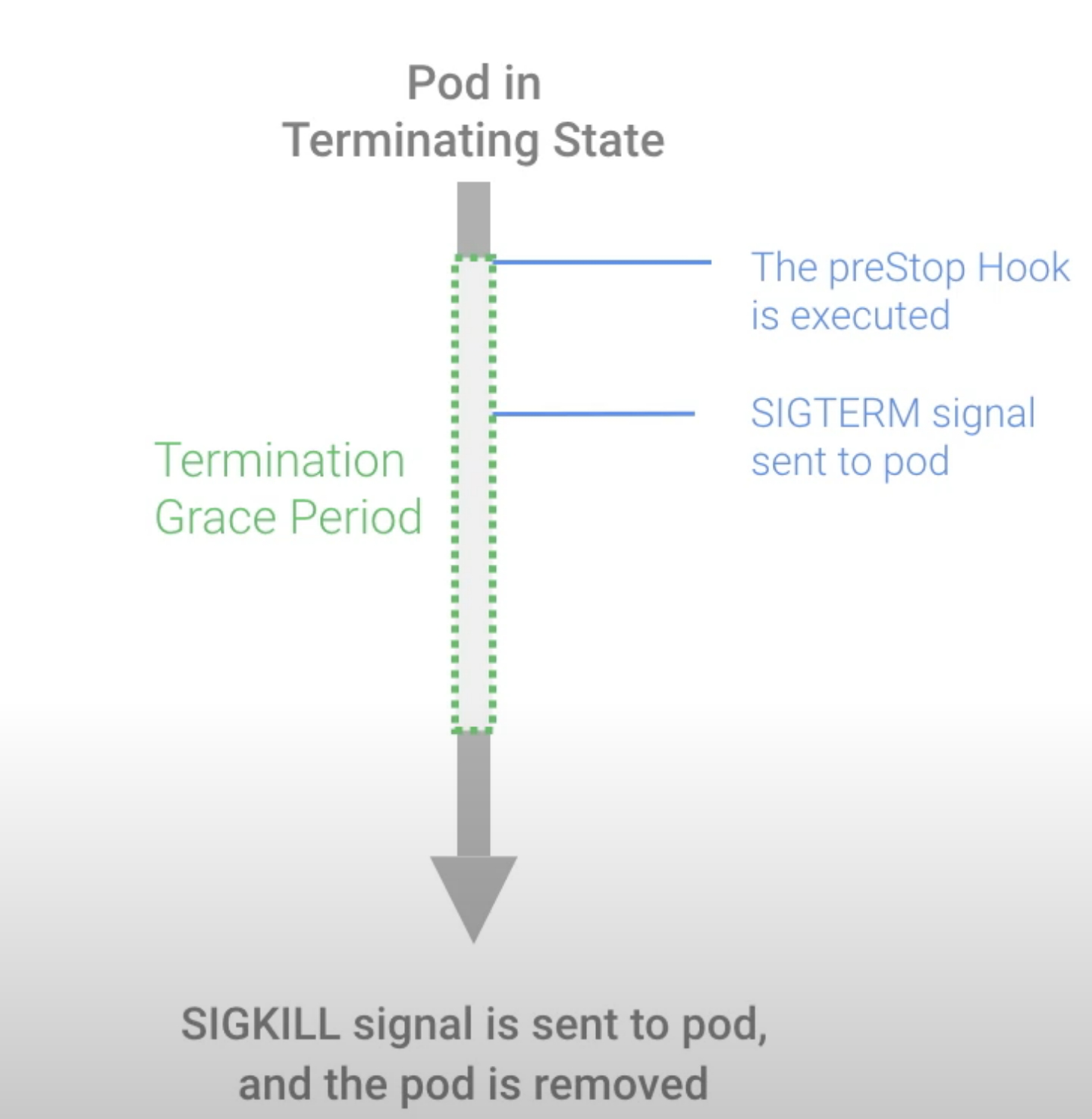
当 Kubernetes 杀死一个 pod 时,会发生以下 5 个步骤:
1、 Pod 切换到终止状态并停止接收任何新流量,容器仍在 pod 内运行。
2、 preStop 钩子是一个特殊的命令或 HTTP 请求被执行,并被发送到 pod 内的容器。
3、 SIGTERM 信号被发送到 pod,容器意识到它将很快关闭。
4、 Kubernetes 等待宽限期 (terminationGracePeriodSeconds)。此等待与 preStop hook 和 SIGTERM 信号执行并行(默认 30 秒)。因此,Kubernetes 不会等待这些完成。如果这段时间结束,则直接进入下一步。正确设置宽限期的值非常重要。
5、向 pod 发送 SIGKILL 信号,然后移除 pod。如果容器在宽限期后仍在运行,则 Pod 被 SIGKILL 强行移除,终止完成。
当Kubernetes应用做了服务网格sidecar注入,需先保证业务pod和istio-proxy pod启动顺序和停止顺序,避免容器在重启和更新的时候有流量异常,默认阿里ASM开启了holdApplicationUntilProxyStarts和HoldProxyUntilApplicationEnds功能。另外容器应用的优雅停止,需要根据实际情况配置preStop webhook脚本以及terminationGracePeriodSeconds时间。
原则5:正确配置存活探针及就绪探针
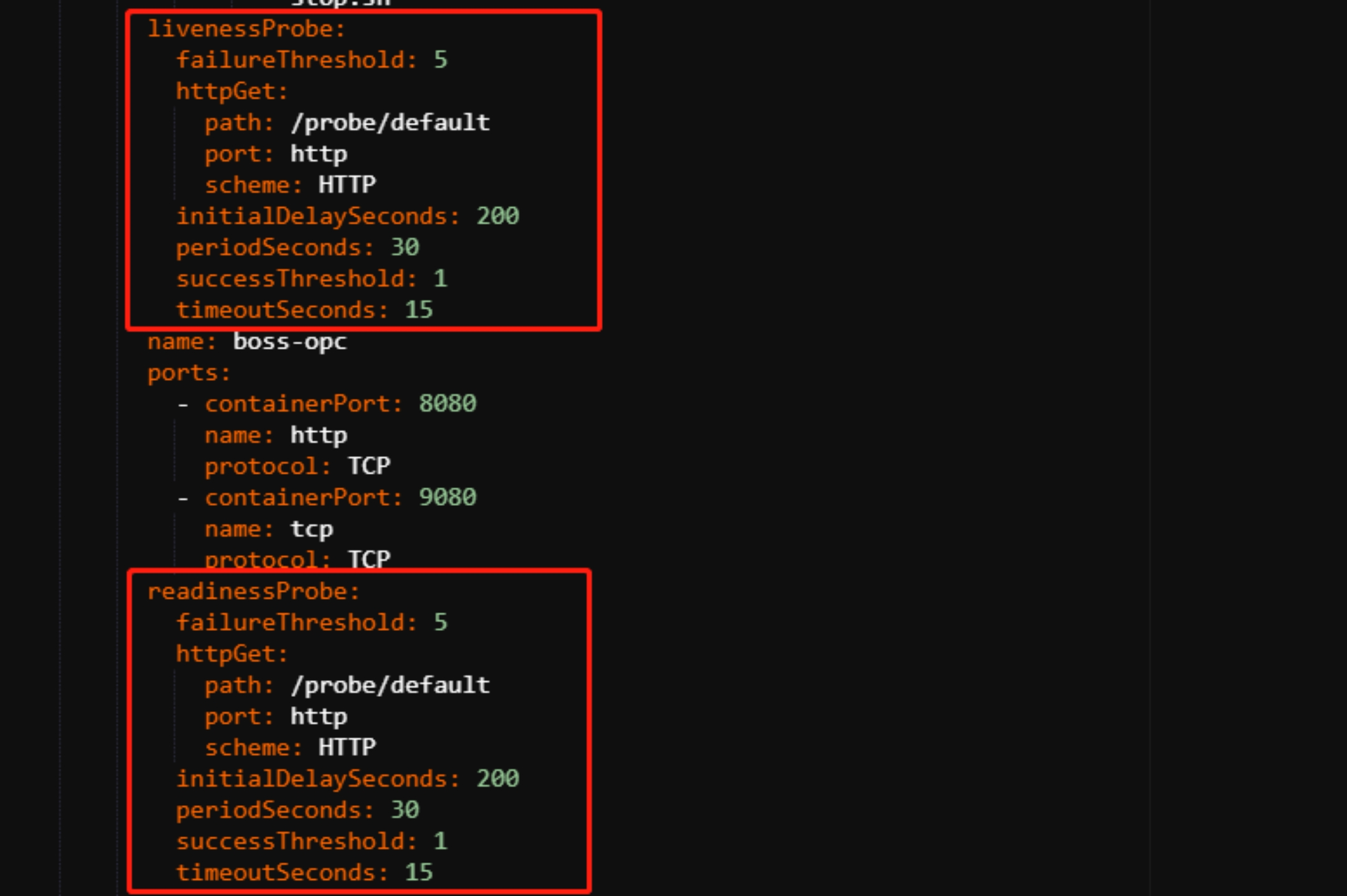
分布式系统和微服务体系结构的挑战之一是自动检测不正常的应用程序,并将请求(request)重新路由到其他可用系统,恢复损坏的组件。健康检查是应对该挑战的一种可靠方法。使用 Kubernetes,可以通过探针配置运行状况检查,以确定每个 Pod 的状态。
就绪探针用于判断容器是否启动完成,即容器的Ready是否为True,可以接收请求,如果ReadinessProbe探测失败,则容器的Ready将为False,控制器将此Pod的Endpoint从对应的service的Endpoint列表中移除,从此不再将任何请求调度此Pod上,直到下次探测成功。通过使用Readiness探针,Kubernetes能够等待应用程序完全启动,然后才允许服务将流量发送到新副本。
存活探针用于判断容器是否存活,即Pod是否为running状态,如果LivenessProbe探针探测到容器不健康,则kubelet将kill掉容器,并根据容器的重启策略是否重启。如果一个容器不包含LivenessProbe探针,则Kubelet认为容器的LivenessProbe探针的返回值永远成功。
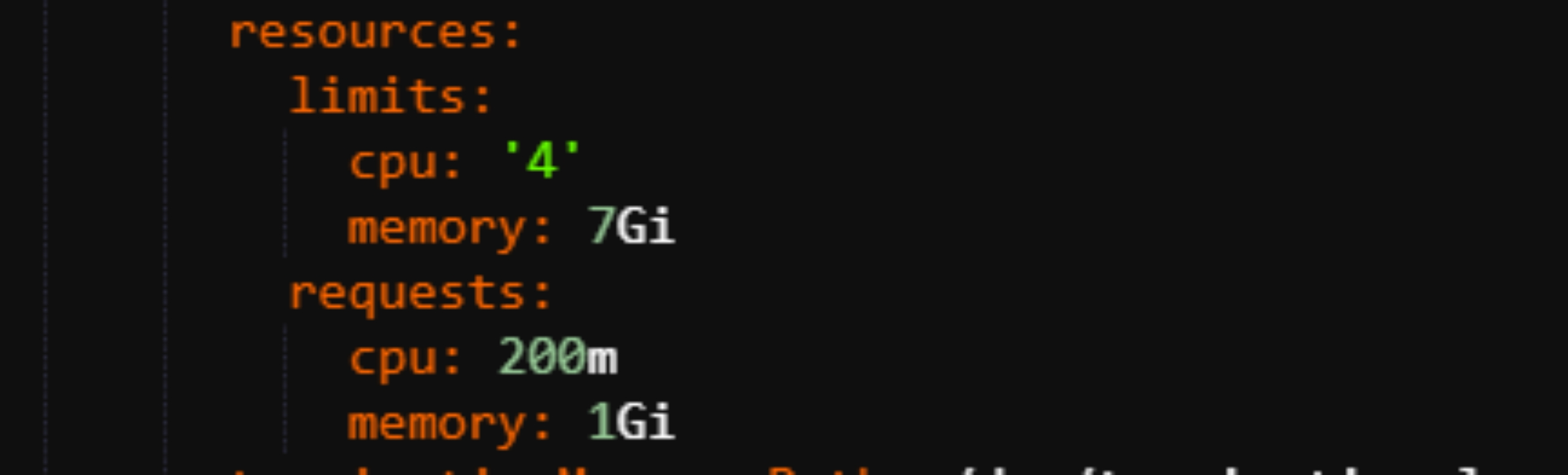
原则6:资源请求与限制
不要将请求和限制设置得太低!一开始这可能很诱人,因为它允许集群运行更多的 Pod。但在高峰期它们的QPS将被限制在指定的数量。而扩大规模实际上意味着每个部署的 Pod 占用更多的资源,但是整体性能可能会更差。也不要将请求和限制设置太高,这会造成资源的极大浪费。
如何有效的设置resources request和limits ,在降本的同时提高资源的利用率,研发同学可以结合prometheus和grafana历史数据,根据趋势图以及峰值数值合理配置资源参数。
因java应用在启动时cpu会飙升一段时间(jvm在启动的时候会装载并连接所有除反射以外的类,而class文件是二进制的文件,需要从磁盘加载到内存然后解析,这种解析是很耗费cpu的,class文件越多,cpu耗费就越高),在无需关注应用重要程度的情况下,推荐Qos设置为Burstable(limits 与 requests 值设置不同)即可,阿里ack安装的组件如coredns、kube-proxy、网络插件等OomScoreAdj打分很低,在触发系统驱逐状态下不会先行驱逐组件从而影响应用。必须设置为Guaranteed的可联系运维调整。
原则7:可观测性
监控、日志记录和链路跟踪是可观察性的三大支柱。SRE 的 “四个黄金信号” 是延迟、流量、错误和饱和度。从经验上看,使用特定于应用程序的指标跟踪这些监控信号比使用通用基础资源获得的原始指标要有用得多。
如容器异常重启报警,可及时通过阿里ACK事件界面查看重启原因(事件默认保留一个小时),prometheus监控查看cpu、mem、net、fs读写状况,阿里ARMS查看jvm以及链路状态等请求情况,以及阿里sls 日志服务查看重启时间点业务日志详细信息来排查。
原则8:容器调度
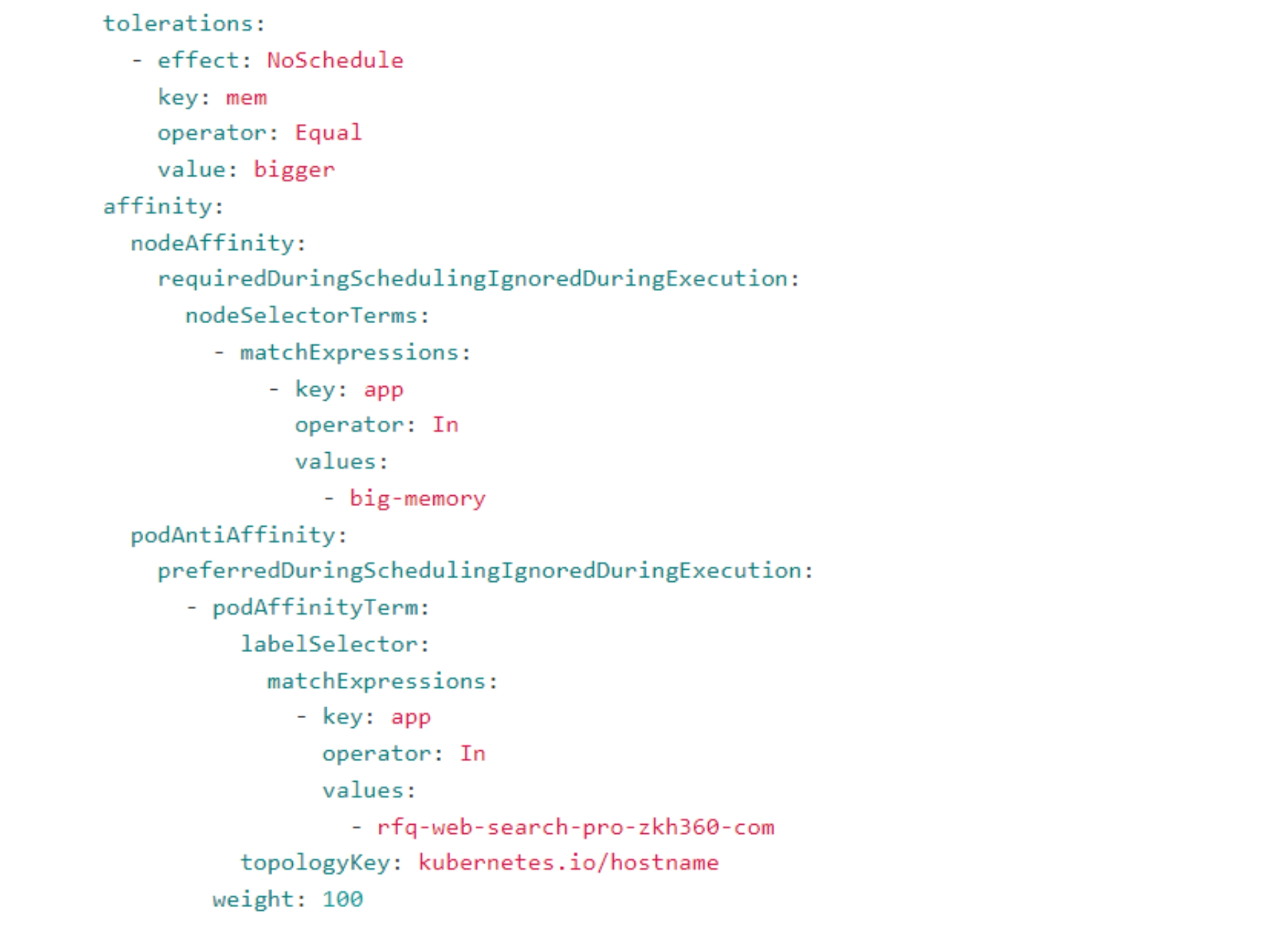
在默认的K8S调度中,一般经过预选和优选即可完成调度,但是生产的实际使用中,考虑到部分业务的特殊性,一般会手动进行一些"指定", K8S 把这些"指定"分为nodeAffinity(节点亲和性)、podAffinity(pod 亲和性) 以及 podAntiAffinity(pod 反亲和性), 这在调度过程中,称之为亲和性调度,亲和性调度可以分成软策略(preferredDuringSchedulingIgnoredDuringExecution )和硬策略
(requiredDuringSchedulingIgnoredDuringExecution)两种方式,软策略意思是如果现在没有满足调度要求要求的话,那就跳过这条策略,继续调度,总结起来就是"有则用之,无则跳过", 而硬策略相对就强硬很多,如果不满足调度策略,则不停重试,直到满足策略。Pod 拓扑传播约束以及亲和性和反亲和性规则可以做到将 Pod 放在一起(以提高网络流量效率)或将它们分散(以实现冗余)保证可用性。
亲和性和反亲和性的作用是为了让pod可以根据需要调度到自己想分配的一个或者一组node上,污点的作用其实就是反过来,就是给node打上一个特殊的标签,让该node不再被分配pod,除非该pod容忍了该污点。