基本概念
Kafka 是一个分布式流处理平台,主要用于处理大规模的实时数据流。它最初由 LinkedIn 开发,现在是 Apache 软件基金会的一部分。Kafka 可以高效地进行消息传递、数据流处理和日志聚合,广泛应用于实时数据分析、事件驱动架构以及大数据处理等场景。
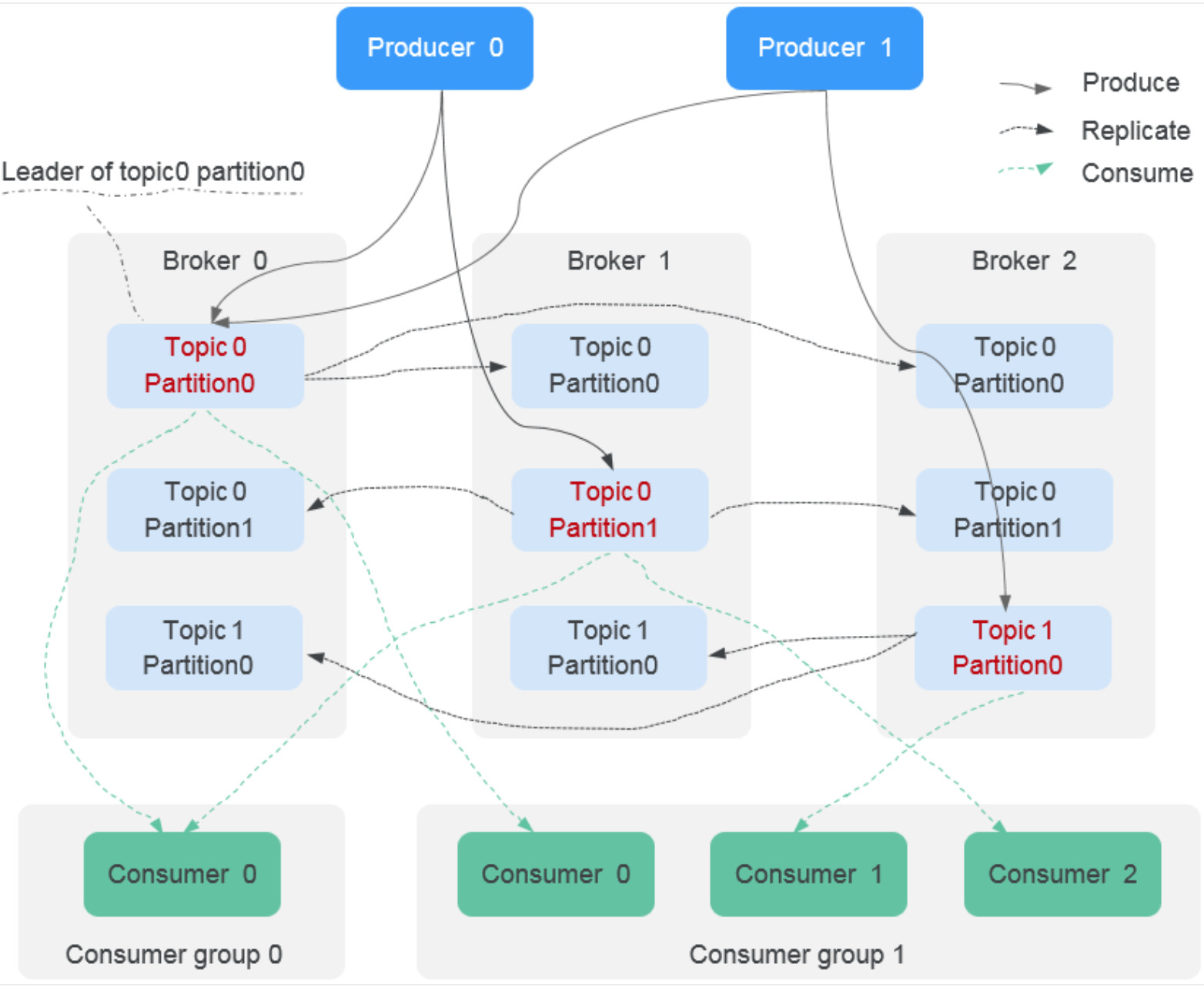
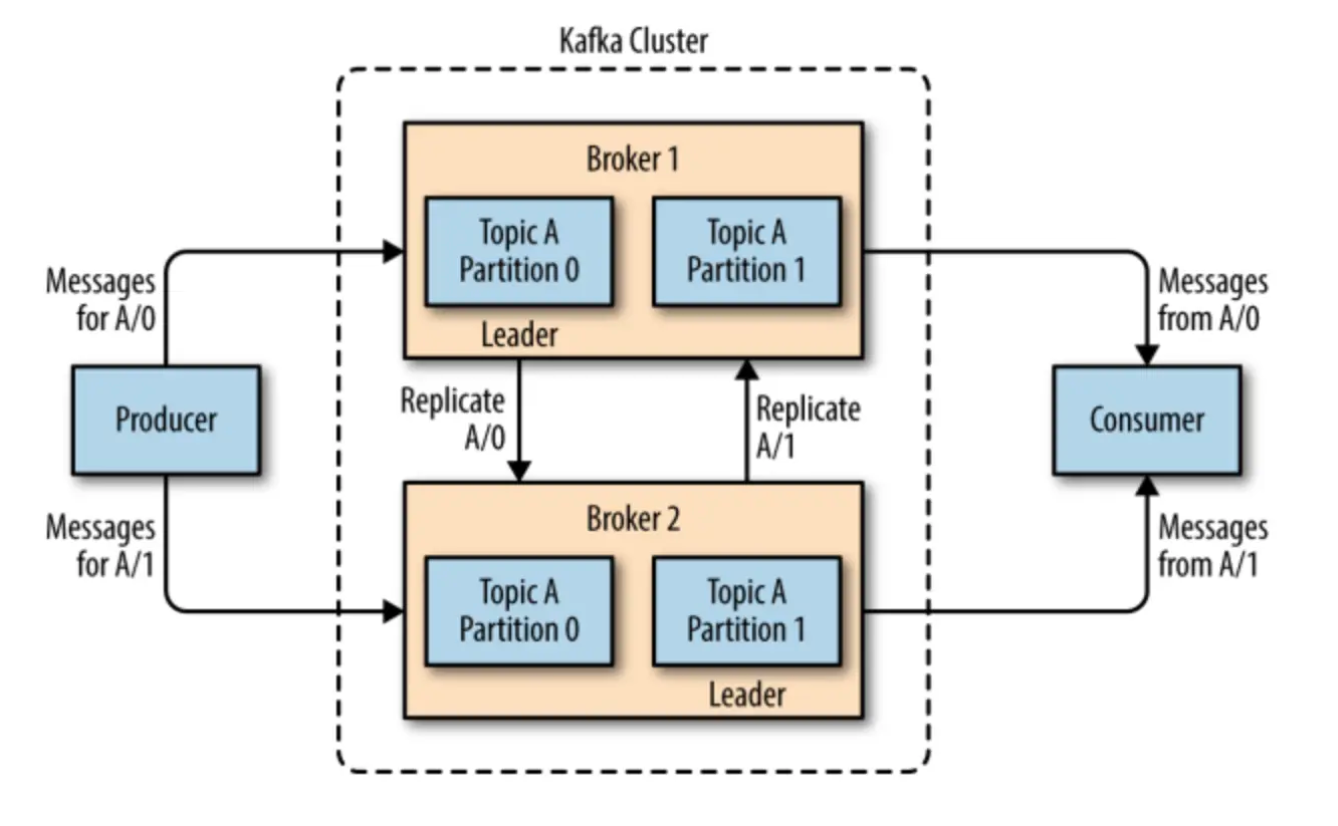
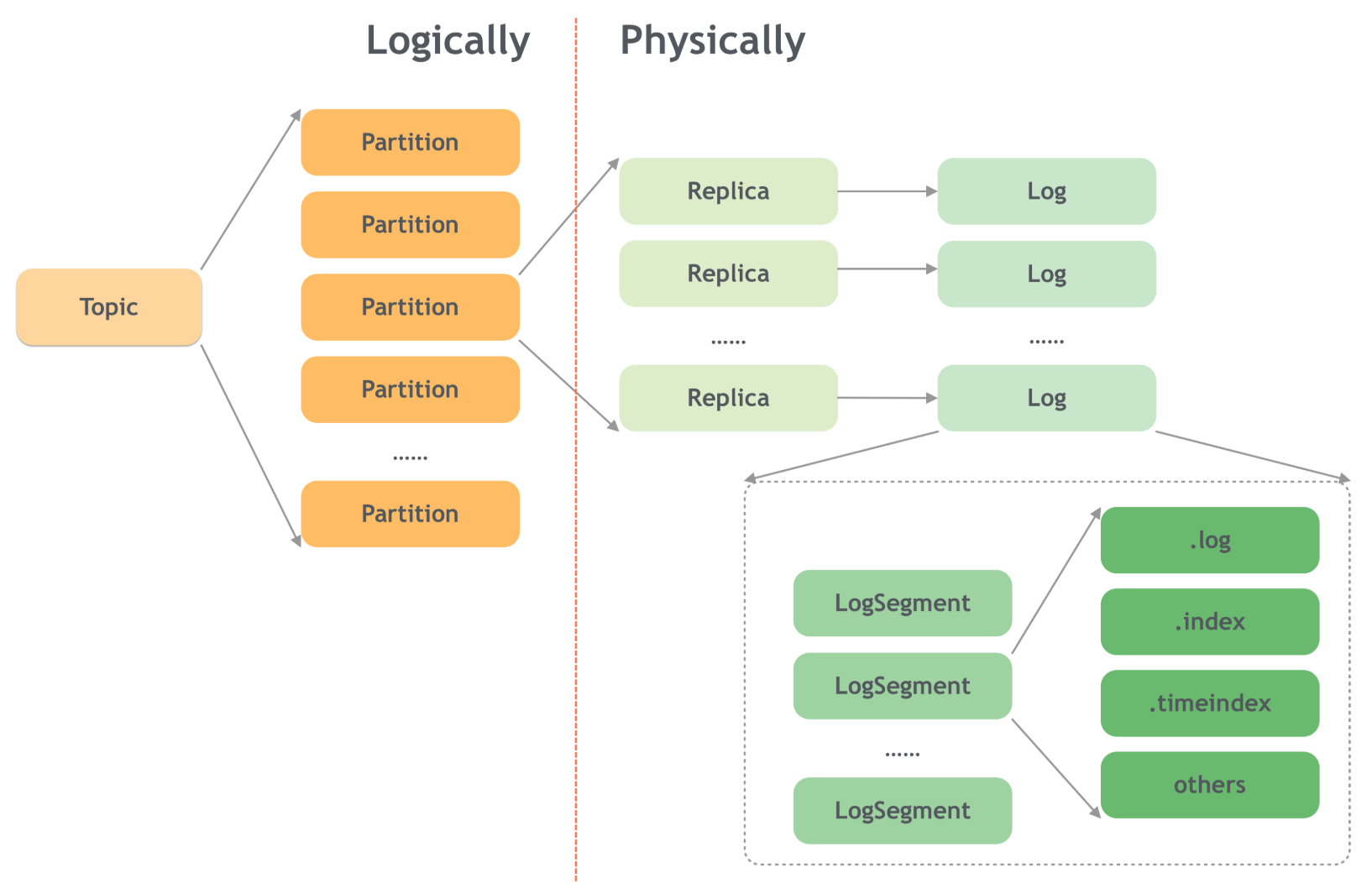
Kafka 的核心概念:
- Producer(生产者):
- 负责将数据发送到 Kafka 中的一个或多个主题(Topic)。生产者通常是数据源,如传感器、日志生成器等。
- Consumer(消费者):
- 消费者从 Kafka 的主题中读取数据。一个主题可以有多个消费者,消费者组允许多个消费者并行处理不同分区的数据。
- Topic(主题):
- Kafka 中的消息会被组织到不同的主题中。生产者将数据写入到特定的主题,而消费者则从主题中读取数据。
- Partition(分区):
- 每个主题可以有多个分区,分区是 Kafka 中的基本存储单位。通过分区,Kafka 可以实现消息的并行处理和数据的水平扩展。
- Broker(代理):
- Kafka 的服务器,负责接收、存储、转发数据。每个 Kafka 集群由多个 Broker 组成,具有高可用性和容错性。
- Zookeeper(协调者):
- Kafka 使用 Zookeeper 来进行集群管理和协调。它帮助 Kafka 管理各个 Broker 的元数据、故障检测和选举过程。
- Consumer Group(消费者组):
- 消费者组是 Kafka 中的一个重要概念,它允许多个消费者共同消费同一个主题的消息。每个消费者组中的每个消费者只会消费主题的某些分区的消息,这样可以实现负载均衡。
- Offset(偏移量):
- Kafka 会为每个消息分配一个唯一的偏移量,消费者通过偏移量来跟踪自己消费的位置。偏移量是持久化存储的,即使消费者断开连接,也能在恢复时继续消费未处理的消息。
Kafka 的特点:
- 高吞吐量:Kafka 可以每秒处理百万级的消息,适合大数据量、高并发的场景。
- 分布式:Kafka 是一个分布式系统,数据可以分布在多个节点上进行存储,支持横向扩展。
- 容错性:Kafka 通过复制机制确保数据的高可用性,即使某些节点发生故障,数据也不会丢失。
- 持久性:消息数据可以长时间保存在 Kafka 中,消费者可以在任何时候读取这些数据。
- 实时性:Kafka 支持实时的数据流处理,能够支持低延迟的数据传输和处理。
Kafka 的常见应用场景:
- 日志收集:Kafka 常用于收集和处理应用程序或系统日志,能够高效地将日志发送到集中式的日志管理平台。
- 实时数据流处理:用于实时分析和处理数据流,例如在线推荐、实时数据监控等。
- 事件驱动架构:通过 Kafka 实现不同系统间的事件驱动通信,解耦系统之间的依赖关系。
- 数据集成:Kafka 可以作为不同数据源之间的数据管道,支持从多个系统采集数据,并将其传递到下游系统。
在 Kafka 中,分区(Partition)和副本(Replica)是两个重要的概念,它们的作用和目的不同:
1. 分区(Partition)
- 定义:分区是 Kafka 中的一种数据组织方式。每个 Kafka 主题(Topic)可以由多个分区组成。每个分区是一个有序的、不可变的消息日志,Kafka 会将消息按顺序写入分区,并为每条消息分配一个唯一的偏移量(Offset)。
- 作用:
- 数据分布:通过分区,Kafka 将消息分散存储在不同的服务器上,从而能够横向扩展,提高吞吐量。
- 并发性:分区允许多个消费者并行处理不同分区的数据,提升系统的并发处理能力。
- 负载均衡:每个分区可以被分配给不同的消费者实例,这样可以实现负载均衡。
2. 副本(Replica)
- 定义:副本是 Kafka 中为了保证数据的高可用性和容错性,对每个分区进行复制的机制。每个分区可以有多个副本,副本存储在不同的 Kafka 代理(Broker)上。
- 作用:
- 数据容错:副本的存在确保了 Kafka 在单个服务器发生故障时,依然能够通过其他副本恢复数据,保证消息不丢失。
- 高可用性:副本机制使得 Kafka 可以在某些节点失效时,继续提供服务。例如,如果一个副本的主副本(Leader)不可用,Kafka 可以选举一个新的主副本来继续提供服务。
-
复制策略:Kafka 使用“Leader-Follower”模型,每个分区都有一个主副本(Leader)和多个从副本(Follower)。所有的写操作都发生在 Leader 上,Follower 会从 Leader 获取更新。
-
分区决定了消息的物理存储位置和消息的处理方式,它是 Kafka 消息系统的基本单位。
- 副本则是对分区数据的冗余存储,用于提高 Kafka 的容错能力和可用性。